
Azure Data Factory data flow to copy activity
Recently I worked on a fun and challenging task to replace data flows in our Azure Data Factory (ADF) pipeline(s) with copy activities.
The goals that were set:
- reduce costs
- reduce complexity
- improve performance
Overview
Before the changes were made there was an overly complex (set of) pipeline(s). The good thing about the setup was that is was working properly, so this is not to blame anyone. But looking back the team thought we could simplify and in the process save on the costs.
In this part of the process the pipeline loops over the source files and using a switch component passed onto a specific data flow with a very simple transformation (adding some columns and group by).
Data Flows are great, but they come with a cost (actual costs). The low amount of transformations didn’t justify these higher costs.
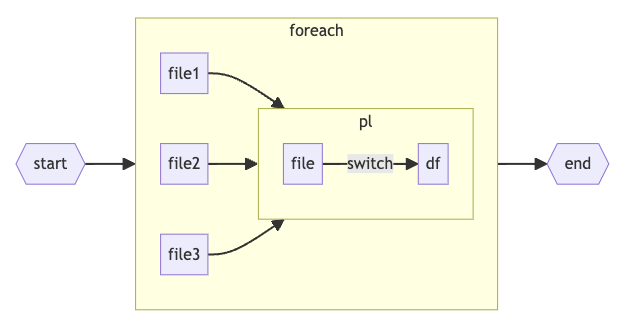
In the above process flow, for the three input files a sub-pipeline would be invoked and based on the input parameters a data flow was invoked from there.
Solution
By removing the switch in the existing situation we could also eliminate a pipeline call. And we could remove a lot of specific code. Foreach file an data flow and data set were created, this added to the reduced complexity.
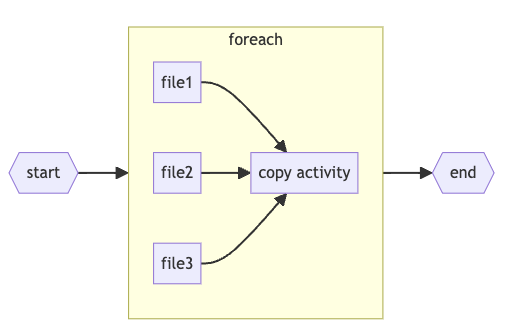
With this changed pipeline, the costs of our ADF were reduced with ~30%!
So this meets 2 out the 3 goals. Let’s talk about the performance next
Performance
Unfortunately we weren’t able to inprove the performance of our data loading, to stay positive.
To make things interesting, our process ingests the source files into an Azure SQL database and an on-premises SQL Server. Both database are using the same process; the on-premises database is loaded in ~45 minutes (similar as before the changes), but the Azure SQL database is taking ~90 minutes! This 100% increase is a total surprise, as the Azure SQL database is in closer proximity to the source files compared to the on-premises database.
Managed private endpoints
In the search for the reason why the ingestion is taking twice as long, it was noticed that the linked service to the Azure SQL Database was not using the (approved) managed private endpoint.
The linked service gets the connection string from KeyVault and couldn’t change it to use the managed private endpoint.
By creating a separate linked service and selecting the target database from the menu, it was possible to use the managed private endpoint.
Case closed?
The first thought that came was that it was now solved, just use the changed linked service and check the performance. But I couldn’t be more wrong. By changing, or even creating a new linked service the mapping of the source files with the target tables goes awry. This is not expected per this part of the Microsoft documentation.
By default, copy activity maps source data to sink by column names in case-sensitive manner. If sink doesn’t exist, for example, writing to file(s), the source field names will be persisted as sink names. If the sink already exists, it must contain all columns being copied from the source. Such default mapping supports flexible schemas and schema drift from source to sink from execution to execution - all the data returned by source data store can be copied to sink.
To get around this, I changed the copy activity to create a new destination table instead of the existing one. This worked, but this is not desired. But with the new table, I was able to compare the two tables. Based on the naming of the columns, there is no difference. Later on I tried to remove the indexes on the columns, but to no avail. Next I tried to have the same column order as the automatic created table, again to no avail.
For now I forgot to check if at least the performance is better when using the copy activity over the managed private endpoint, so I will check that and update this post here.
If anyone else has some suggestions what can be done to get the performance back to being similar to the ingestion to the on-premises database. Pleae reach out to me via linkedIn.
Conclusion
So far the conclusion is a bit dissapointing. Happy that ~30% of the costs were cut, but at the expense of having the data processing taking twice as long. The complexity reduction is real and aids troubleshooting.
Hopefully I can update this post in the near future with a more satisfying conclusion.